
Intro or introspective sort is a sorting weapon used by the STL library in C++ and array sorting in the swift programming language. In simple terms, it is currently, the best sorting algorithm. In this article, we dive into the details of the intro sort algorithm and analyze why it is regarded as the best sorting algorithm.
Intro sort is a hybrid comparison-based sorting algorithm that consists of three sorting phases. These three sorting phases or algorithms minimize the run time. The three sorting algorithms used in intro sort are Quicksort, Insertion sort, Heapsort.
Note: Introsort is not stable.
This means that two objects with equal values may or may not appear in the same order in sorted output as they appear in the input unsorted array
Why do we need Intro sort?
To understand the importance of intro sort let us briefly understand the drawbacks of other commonly used sorting algorithms.
Quicksort
Quicksort is one of the efficient algorithms based on the divide and conquer method. It has a complexity of NlogN in its best and average case but has O(N²) in its worst time performance. The complexity of Quicksort depends upon the choice of the pivot element and the depth of the recursion tree. It also uses O(N) auxiliary space.
Heapsort
Heapsort always has a time performance of O(NLogN) which is significantly better than the worst time complexity of quicksort O(N²). So, is heapsort the best sorting algorithm? The answer is no. In quicksort, no swapping of elements occurs if the array is sorted whereas, in heapsort, the swapping of elements is unavoidable. The best thing about heapsort is that the time complexity remains O(nlogn) irrespective of the recursion depth.
Mergesort
Mergesort is also a divide and conquer algorithm with a time complexity of O(NlogN). Mergesort can be used irrespective of the size of the data sets. Mergesort works well with LinkedList whereas quicksort is better with arrays. Generally, with memory constraints, quicksort outperforms merge sort.
Insertion sort
Insertion sort is simple and easy to implement. Insertion sort is good for small data sets but the performance deteriorates with the increase in the size of the data list. It has minimal space requirements but has a time performance of O(N²).
Why is mergesort not used?
As stated earlier, mergesort has a space complexity of O(N) and in practical application, quicksort outperforms merge sort on subjected to sorting arrays.
When to switch from quicksort to heapsort?
The decision to switch from quicksort to heapsort is based on the depthlimit. The depthlimit represents the maximum depth of recursion up to which quicksort runs without moving to its worst time performance of O(N²). This ensures that the time complexity of intro sort remains O(nlogn) in all cases. The depthlimit for the intro sort is chosen as 2*logN (N is the number of elements) based on research.
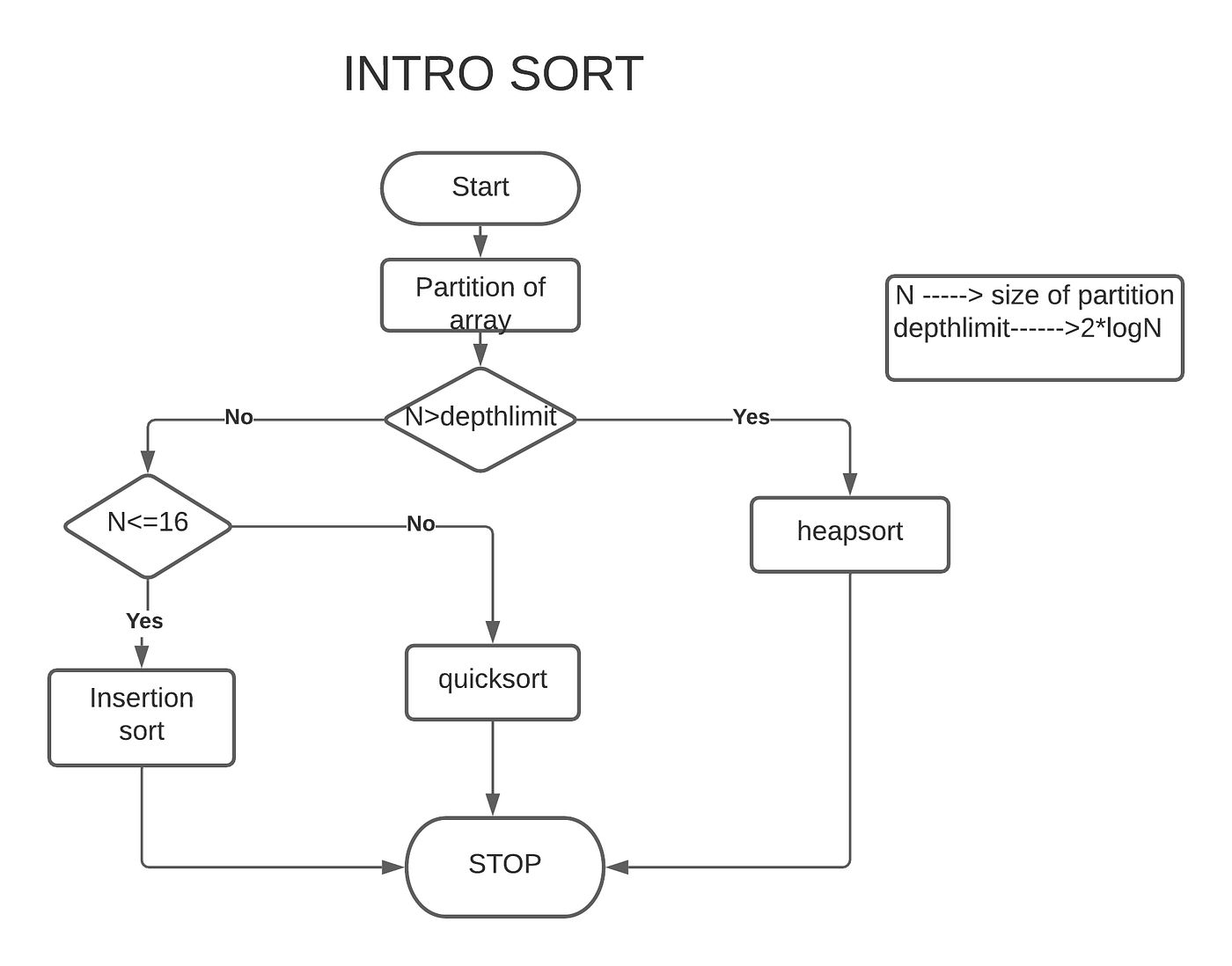
Based on the above analysis, the working of intro sort can be summarized as,
- Intro sort begins with quicksort and if the recursion depth exceeds the depthlimit of intro sort, switching to heapsort takes place.
- If the number of elements is few, insertion sort takes place.
Therefore, the first step is to create a partition. After creating a partition, three cases arise,
- If the partition size is greater than the depthlimit i.e 2*logN, switching to heap sort takes place.
- If the partition size is too small, switching to insertion sort takes place. The constant below which insertion sort is used is chosen to be 16 based on research. Therefore, if the size of the partition is less than or equal to 16, insertion sort takes place.
- If the partition size is greater than 16 and less than the depthlimit (2*logN), quicksort is performed.
FLOWCHART
PSEUDO CODE
sort(A : array):
depthLimit = 2xfloor(log(length(A)))
introsort(A, depthLimit)
introsort(A, depthLimit):
n = length(A)
if n<=16:
insertionSort(A)
if depthLimit == 0:
heapsort(A)
else:
p = partition(A)
introsort(A[0:p-1], depthLimit — 1)
introsort(A[p+1:n], depthLimit — 1)
Implementation in C++
/*The most popular C++ STL Algorithm- sort()
uses Introsort. */
#include<bits/stdc++.h>
using namespace std;
// A utility function to swap the values pointed by
// the two pointers
void swapValue(int *a, int *b)
{
int *temp = a;
a = b;
b = temp;
return;
}
/* Function to sort an array using insertion sort*/
void InsertionSort(int arr[], int *begin, int *end)
{
int left = begin — arr;
int right = end — arr;
for (int i = left+1; i <= right; i++)
{
int key = arr[i];
int j = i-1;
while (j >= left && arr[j] > key)
{
arr[j+1] = arr[j];
j = j-1;
}
arr[j+1] = key;
}
return;
}
// A function to partition the array and return
// the partition point
int* Partition(int arr[], int low, int high)
{
int pivot = arr[high]; // pivot
int i = (low — 1); // Index of smaller element
for (int j = low; j <= high- 1; j++)
{
if (arr[j] <= pivot)
{
i++;
swap(arr[i], arr[j]);
}
}
swap(arr[i + 1], arr[high]);
return (arr + i + 1);
}
// A function that find the middle of the
// values pointed by the pointers a, b, c
// and return that pointer
int *MedianOfThree(int * a, int * b, int * c)
{
if (*a < *b && *b < *c)
return (b);
if (*a < *c && *c <= *b)
return ©;
if (*b <= *a && *a < *c)
return (a);
if (*b < *c && *c <= *a)
return ©;
if (*c <= *a && *a < *b)
return (a);
if (*c <= *b && *b <= *a)
return (b);
}
// A Utility function to perform intro sort
void IntrosortUtil(int arr[], int * begin,
int * end, int depthLimit)
{
// Count the number of elements
int size = end — begin;
// If partition size is low then do insertion sort
if (size < 16)
{
InsertionSort(arr, begin, end);
return;
}
// If the depth is zero use heapsort
if (depthLimit == 0)
{
make_heap(begin, end+1);
sort_heap(begin, end+1);
return;
}
// Else use a median-of-three concept to
// find a good pivot
int * pivot = MedianOfThree(begin, begin+size/2, end);
// Swap the values pointed by the two pointers
swapValue(pivot, end);
// Perform Quick Sort
int * partitionPoint = Partition(arr, begin-arr, end-arr);
IntrosortUtil(arr, begin, partitionPoint-1, depthLimit — 1);
IntrosortUtil(arr, partitionPoint + 1, end, depthLimit — 1);
return;
}
void Introsort(int arr[], int *begin, int *end)
{
int depthLimit = 2 * log(end-begin);
// Perform a recursive Introsort
IntrosortUtil(arr, begin, end, depthLimit);
return;
}
// A utility function ot print an array of size n
void printArray(int arr[], int n)
{
for (int i=0; i < n; i++)
printf(“%d “, arr[i]);
printf(“\n”);
}
// Driver program to test Introsort
int main()
{
int arr[] = {3, 1, 23, -9, 233, 23, -313, 32, -9};
int n = sizeof(arr) / sizeof(arr[0]);
// Pass the array, the pointer to the first element and
// the pointer to the last element
Introsort(arr, arr, arr+n-1);
printArray(arr, n);
return(0);
}
OUTPUT
313 -9 -9 1 3 23 23 32 233
Time Complexity
Best Case — O(N log N)
Average Case — O(N log N)
Worse Case — O(N log N)
where N = number of elements to be sorted.
Auxiliary Space
It may use O(log N) auxiliary recursion stack space(quicksort).
Comparison
